Solutionsfor Business
Software und Strategien für den erfolgreichen Mittelstand
Alle Funktionen passen zu „Columnar“
Oracle 12c bekommt „In Memory“-Option
Mit der Version 12.0.2 der Datenbank Oracle 12c zieht der Datenbank-Primus in Bezug auf die In-Memory-Technologie nach: Die Kombination aus „Columnar-Technologie“ und In-Memory-Technik steht ab Mitte 2014 für Oracle 12c zur Verfügung: Der große Vorteil gegenüber anderen derartigen Datenbanken: Es müssen keine Anwendungen geändert oder gar umgeschrieben werden und auch die komplette Betriebsumgebung aus dem Enterprise-Umfeld steht ohne Modifikationen zur Verfügung. Zudem ist diese Option auf allen von Oracle unterstützten Plattformen einsatzbereit.
In-Memory

Bei der „Columnar-Technik“ handelt es sich um eine Technologie, die schon seit Jahren mit dem Row-basierten Ansatz konkurriert. Davon zeugen viele wissenschaftliche Arbeiten, die die Vorteile der verschiedenen Welten herausgearbeitet haben. Bei der Columnar-Technik erfolgt die Speicherung der Informationen anders als bei klassischen Systemen.
Columnar wurde beispielsweise schon über 15 Jahre beim damaligen Datenbankhersteller Sybase (mittlerweile von SAP übernommen) eingesetzt, wobei es mit Sybase IQ ein Konzept speziell für Auswertungen und Anwendungen im Bereich von Data Warehouse gab, doch das war damals nicht als „In Memory“ ausgeführt. In der wissenschaftlichen Diskussion wurde vor allem die Frage diskutiert, was besser ist,
• Row-basierend, sprich bei der Speicherung ist ein Record aufgeteilt in mehrere Spalten, und so wird der Record auch abgespeichert,
• oder aber „Columnar“. Dabei werden einzelne Spalten im Datenbankblock aufgefächert und die Spalten auf verschiedene Datenbankblöcke aufgeteilt.
Bei Oracle selbst wurde bereits in den früheren Datenbankversionen intensiv mit der Ablage der „heißen“ Daten im Arbeitsspeicher gearbeitet – doch das wurde nicht als „In Memory“ bezeichnet. Was dabei allerdings noch gefehlt hat, war die spaltenorientierte Speicherung zusammen mit der Technik „In Memory“. Diese Kombination wurde nun auf der letzten Oracle World angekündigt. Gleichwohl stellt das im Oracle-Universum lediglich eine zusätzliche Option für das Datenbankformat dar und passt entsprechend nahtlos in die Oracle-12c-Umgebung.
Datenbankabfragen beschleunigen
Zu den Techniken, die Oracle verwendet, um die Abarbeitung von Datenbankanfragen zu beschleunigen, gehören schon seit Längerem Technologien, die intensiv auf den Arbeitsspeicher zugreifen: Die sehr großen Datenbank-Caches (bei denen die Daten allerdings im traditionellen Modell – also Row-weise – abgelegt werden) sind hier zu nennen – sie können durchaus mehrere TB groß sein. Ein gut eingeschwungenes Oracle-Datenbanksystem weist dabei eine Cache-Trefferrate von 95 Prozent und mehr auf. Sprich, mindestens 95 Prozent der Zugriffe laufen über den Arbeitsspeicher und können direkt von dort bedient werden. Das System muss nicht auf die langsameren Festplatten zugreifen, um die Daten von dort zu laden.
Ein Beispiel: Wer eine Fahrkartenbuchung auf dem System der Deutschen Bahn ausführt, bei dem hält das Datenbanksystem von Oracle die Angaben über die meisten Bahnhöfe im Cache. Nur Bahnhöfe, die ganz selten nachgefragt werden, müssen von Festplatte nachgeladen werden. Weitere Optimierungen bei Oracle-Datenbanken im traditionellen Modell umfassen das „Pinnen“ von ganzen Tabellen im Arbeitsspeicher – dabei bleiben die betreffenden Tabellen fest im Arbeitsspeicher verankert. Diese Option kann der Datenbankadministrator für Tabellen explizit vorgeben.
Eine weitere Optimierung wird durch das Vorhalten von „Query Result Cache“ erzielt: Dabei wird eine Anfrage an eine Datenbank gestellt, wobei man das Ergebnis der Anfrage im Cache halten möchte. Bei einer zweiten, identischen Abfrage, wird das zugehörige Ergebnis dann gleich direkt aus dem Cache geliefert. Ein Test bei Oracle, der auf einer „reduzierten Hardware“ in Form eines Notebooks mit 105 Millionen Records lief, hat ergeben: Die Anfrage ist beim zweiten Mal aus dem Arbeitsspeicher bedient worden und hat dann nur noch eine Antwortzeit im Mikrosekundenbereich benötigt.
Zu all diesen heute bereits verfügbaren Optimierungsfunktionen kommt nun die Columnar-Technologie hinzu. Es handelt sich dabei um eine Weiterentwicklung für die Datenbankversion 12c. Als eine sehr wichtige Vorbedingung hat man bei Oracle ausgegeben, dass beim Einsatz der Columnar-Technologie in Verbindung mit dem In Memory-Konzept, keine bestehende Funktionalität obsolet werden darf. Kompatibilität und Funktionen der bisherigen Oracle-Umgebung müssen voll und ganz gewahrt bleiben. Vor allem sind die für den Betrieb in Enterprise-Umgebungen nötigen Funktionen, wie das Sichern oder das Rollback etc., weiterhin verfügbar – auch mit dem neuen Konzept.
Für die „Columnar-In Memory“-Option von Oracle stand daher im Pflichtenheft, dass die bestehende Infrastruktur nutzbar bleiben muss, wozu Hochverfügbarkeit, Sicherheit, Backup/Restore, Zugriff über SQL und auch PL/SQL und Java gehören. Generell müssen die bestehenden Anwendungen von In-Memory und Columnar profitieren, ohne dass man die Applikationen umschreiben muss – optimieren ja, aber nicht umschreiben. Damit will Oracle sicherstellen, dass diese Option nicht nur für neu entwickelte Systeme Nutzen bringt. In aktuellen Oracle-Datenbankumgebungen entscheidet der SQL-Optimizer üblicherweise eigenständig, welche Option gewählt wird.
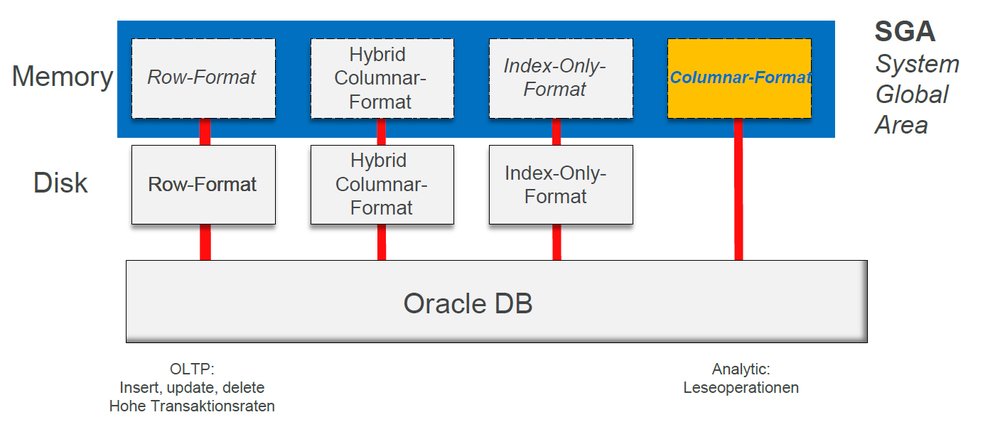
Oracle-basierte Datenbanksysteme haben mehrere Formate: Im „Row-Format“ arbeitet das System mit 8 KByte großen Blöcken. Darin ist der „Primary Key“, aber auch der Datensatz enthalten. Diese Struktur ist auch so auf der Platte abgelegt. Wenn man den Datenbankblock von der Festplatte in den Hauptspeicher transportiert, liegt er dort genauso vor und wird dann auch dort verarbeitet.
Beim „Index-Only-Format“ wird die Tabelle dagegen nicht im klassischen Row-Format angelegt. Vielmehr wird die Tabelle als Index aufgebaut, und Anwendungen bzw. Anfragen gehen nur über den Index in die Tabelle und suchen darüber in den Daten. Physikalisch sieht das dann allerdings etwas anders aus, doch man transportiert das genauso in den Hauptspeicher. Bei bestimmten Konstellationen – daher ist das Index-Only-Format auch nur eine Option – ergeben sich gewaltige Geschwindigkeitsvorteile.
Columnar
Seit Einführung von Exadata gibt es bei Oracle auch das „Columnar-Format“ auf der Disk. Das bedeutet, dass eine Tabelle angelegt und dann quasi gekippt wird. Normalerweise liegt eine Row in einem Datenbankblock. Bei Columnar dagegen enthält ein Block eine Spalte, der nächste Block die nächste Spalte und so weiter.
Wenn man eine ganz bestimmte Spalte heraussuchen möchte, muss man einen oder zwei Blöcke (oder auch mehrere davon) „anschauen“, doch man muss nicht die gesamte Tabelle durchsuchen. Das ergibt Geschwindigkeitsvorteile beim Lesezugriff, zum Beispiel lässt sich dabei auch einiges komprimieren. Wenn ich die Tabelle zunächst auf Disk anlege und anschließend in den Hauptspeicher transportiere, sieht sie dort genauso aus.
Neu eingeführt wird ab Datenbankversion 12.0.2 nun die „In Memory-Columar“-Option. Dazu wird ein neues Format angelegt, wozu es jedoch keine Plattenrepräsentation mehr gibt. Die grundlegende Idee lautet: Immer dann, wenn man eine Tabelle spaltenorientiert anlegen möchte, hat man Columnar und Row sowie Hybrid-Format gleichzeitig – aber eben nicht mehr auf der Festplatte. Der Vorteil: Es muss nichts konvertiert werden, kein Umspeichern ist nötig. Der Datenbankadministrator definiert nur: Ich möchte eine Tabelle haben, die im Columnar-Format existiert und in dem Moment, also beim nächsten Zugriff auf die Tabelle, werden die Daten „gedreht“ (auf Columnar umgestellt) und dann so transformiert im Hauptspeicher abgelegt.
Problemfeld Wiederanlauf
Und falls es einmal zu einem Stromausfall beim Datenbanksystem kommt, gibt es keine großartigen Probleme, denn die anderen Formate sind ja nach wie vor auf der Festplatte vorhanden. Die Synchronisation zwischen den Arbeitsspeicherbereichen erfolgt im Hintergrund und der SQL Optimizer entscheidet, von woher er die Daten holt.
Bei Schreiboperationen auf das „Columnar-In Memory“-Format bedient sich Oracle eines Tricks: Diese Operationen laufen über das Row-Format. Damit kann Oracle alle internen Routinen weiterhin nutzen. Es muss somit in den bestehenden Applikationen nichts geändert werden. Das ist entscheidend für den Einsatz beim Kunden. Die gesamte Infrastruktur der Datenbank bleibt gleich und trotzdem wird bei den Operationen das schnellere Format verwendet. Denn die Columnar-Speicherungsart ist sehr langsam, wenn man Änderungen vornimmt.
Wenn zum Beispiel eine Einfügeoperation für einen Datensatz erfolgt und man verwendet einen Block im Row-Format, dann wird mit nur einer einzigen Operation ein Datensatz mit zum Beispiel 50 Spalten eingefügt. Das geht blitzschnell und ist mittlerweile hoch optimiert. Im Hintergrund werden dann noch einige Indices aktualisiert und fertig ist die komplette Änderung.
Bei Columnar hingegen müssten für den einen Datensatz mit 50 Spalten 50 Datenbankblöcke geändert werden. Das sind dann 50 eigenständige Operationen – anders ausgedrückt: Änderungsoperationen sind bei Columnar eine regelrechte Katastrophe. Doch bei Leseoperationen (wie sie zum Beispiel bei Analysen überwiegend der Fall sind) sieht es wieder ganz anders aus. Daher wechselt kein System direkt auf Columnar, denn das würde zu lange dauern. Sprich, man macht da was anders: Es wird Row-orientiert etwas zwischengespeichert, dann wird ein Delta gebildet und anschließend dieses Delta gespeichert.
Aus Performancegründen macht Oracle 12c Folgendes: Die Daten werden gleichzeitig in beiden Formaten gespeichert. Ein gutes Transaktionssystem schreibt nur selten auf Platte. Nur die Protokolldateien werden mitgeschrieben – um bei einem Ausfall des Systems gerüstet zu sein. Dann muss die Datenbanktransaktion wieder aufgesetzt werden, wodurch ein konsistenter Zustand sichergestellt wird. Wer dabei eine massive Platzverschwendung vermutet, der liegt nicht richtig. Denn im Prinzip erweist sich Columnar als nichts anderes als ein Index: Es beschleunigt den Zugriff, muss aber zuerst angelegt werden.
SQL-Beispiel

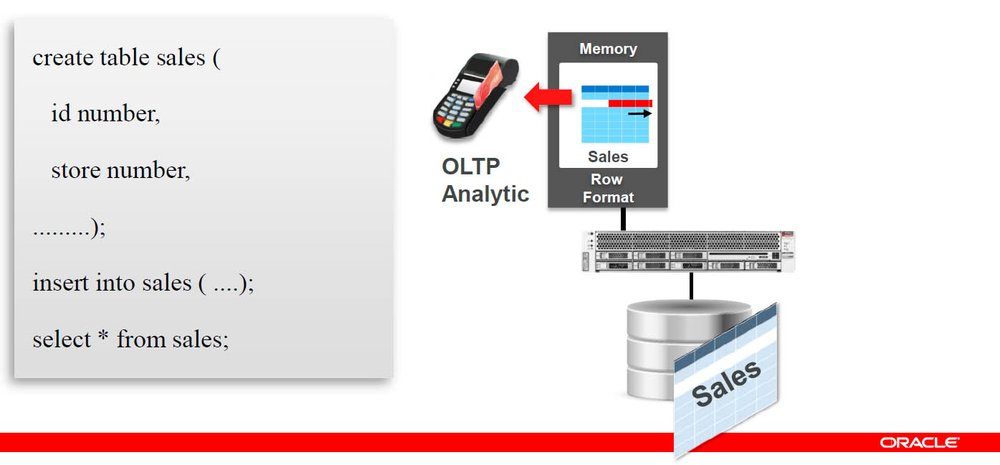
Ein SQL-Beispiel verdeutlicht das Arbeiten mit „Columnar-In Memory“: Mit einem SQL-Befehl wird zuerst eine Tabelle erzeugt. Im Beispiel lautet deren Bezeichnung „sales“. Sie hat beliebige Spalten, wie etwa eine ID und eine Ladennummer (Store ID), das können ganz viele Spalten sein. Ist diese Tabelle angelegt, dann liegt sie physikalisch auf der Platte. Mit Insert-Operationen kann man anschließend Datensätze einfügen, danach können beliebige Anfragen erfolgen. Das wird über Select-Anweisungen gemacht.
Klassisch ist das bisher auf der Platte angelegt, die Insert-Operationen werden zunächst im Arbeitsspeicher ausgeführt, und wenn der Block voll ist, wird er im Hintergrund auf die Platte geschrieben. Bei einer Select-Operation prüft das System, ob die Daten schon bzw. noch im Hauptspeicher liegen. Wenn ja, werden sie sofort genutzt, wenn nicht, müssen sie nachgeladen werden. Unter Umständen sind noch Indices zu erzeugen, doch das sei zunächst mal vernachlässigt.
Verlässt man nun den klassischen Ansatz, kann man aber angeben, dass diese Tabelle als eine „In Memory Tabelle“ definiert wird. Das erfolgt mit dem Befehl:
alter table sales inmemory
Der umgekehrte Befehl lautet:
alter table sales no inmemory
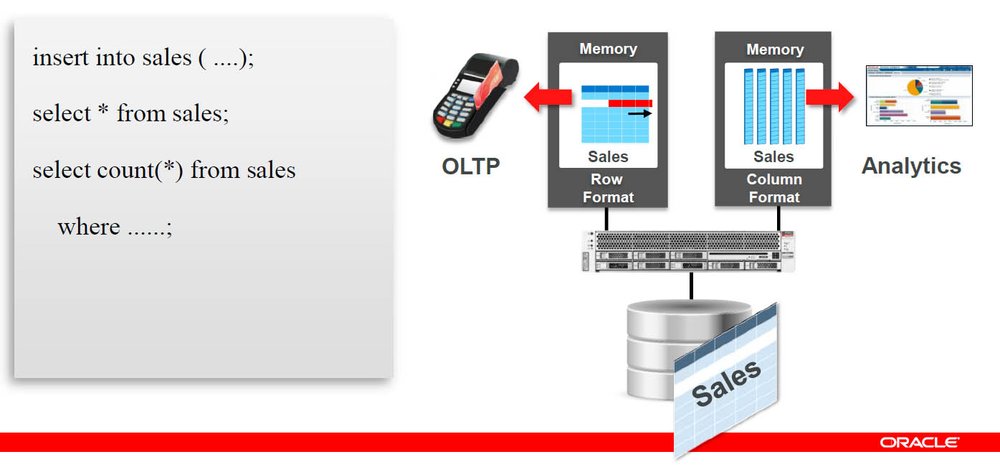
Das ist alles und geht blitzschnell: Hierbei wird nichts umgespeichert, es handelt sich nur um die Definition. Beim ersten Zugriff auf die Tabelle werden die Daten dann geladen – das ist die Standardeinstellung. Es gibt allerdings auch noch die Preload-Option, dabei wird nach der Definition sofort damit begonnen, die Tabelle in den Hauptspeicher zu laden. Ab diesem Moment wird bei einer Select-Anweisung immer vom SQL Optimizer entschieden, welcher Weg genommen werden soll, wobei das am besten geeignete Format der In-Memory-Datenbank gewählt wird (Row-Format oder Column-Format).
Es ist auch machbar, beide Wege zu nehmen. Der SQL Optimizer kennt die passenden Parameter für den Zugriff und berechnet daraus den bestmöglichen Weg – ähnlich wie beim Navigationsgerät im Auto. Der SQL Optimizer macht alles automatisch und nutzt dazu auch die Indices im Hintergrund. Für die Anwendungen aber bleibt alles beim Alten. Die Applikation setzt ja nur den SQL-Befehl ab und nimmt die Ergebnisse entgegen. Damit kann ein Anwender seine Applikation sofort auf die neue Option umstellen und umgehend die Vorteile daraus ziehen. Der Datenbankadministrator entscheidet lediglich für einzelne Tabellen bzw. für einzelne Partitionen einer Tabelle, ob er umschalten will oder nicht.
Größe der Tabelle entscheidet
Wenn eine riesige Tabelle existiert und die liegt partitioniert vor, dann macht es wenig Sinn, die komplette Tabelle als „In Memory“ zu definieren. Hier ist es besser, nur die neuesten Teile der Tabelle als „In Memory“ zu definieren. Die alten Partitionen bleiben außen vor – da ist unter Umständen auch ein Archivieren der alten Partitionen sinnvoll. Zudem bringen Kompressionsmöglichkeiten bei der Columnar-Technik Vorteile mit sich: Mit hoher Kompressionsrate passt mehr in den Hauptspeicher, doch später muss man wieder CPU-Zyklen aufwenden, um die Dekomprimierung hinzubekommen.
Durch diesen neuen Ansatz ergeben sich laut Oracle signifikante Vorteile: Die Systeme werden bei Analytics-Anwendungen etwa um den Faktor 100 schneller. Das ist allerdings auch abhängig von der Art der Anwendung – der Wert kann noch viel höher liegen, jedoch auch darunter. Aber auch für OLTP-Aufgaben beim Row-Format verspricht Oracle eine Verbesserung – etwa um den Faktor 2. Der Grund: Im Normalfall gehören zu jeder Tabelle eine Handvoll Indices. Um Konsistenz zu sichern, werden OLTP-Indices gebildet. Zudem gibt es noch eine Vielzahl von weiteren Indices, um die Abfragen schnell zu machen. Das ist das typische Optimierungsgeschäft: Für spezielle Anfragen werden passende Indices angelegt. So kann es dann schon vorkommen, dass 20 und mehr Indices existieren.
Wenn Änderungen an einer Tabelle erfolgen, müssen die Indices entsprechend angepasst werden. Wenn man den Großteil dieser Indices durch das In-Memory-Format ersetzen kann, dann erfolgen die Zugriffe schneller. Damit kann eine klassische OLTP-Anwendung von In Memory und Columnar profitieren – aber eben auf dem indirekten Weg.
Für den Einsatz in realen Umgebungen ist vor allem wichtig, dass alles möglichst einfach abläuft: Die Datenbank mit der Option wird eingesetzt und anschließend der Speicherbereich angegeben. Danach erfolgt der Befehl, der die Tabelle in den Hauptspeicher pinnt. Alles weitere – die komplette Oracle-Infrastruktur für den professionellen Einsatz in Unternehmen – bleibt ohne Modifikationen verfügbar. Da muss der Anwender nichts ändern. Es ist nur die Entscheidung zu treffen, welche Tabelle künftig „In Memory“ sein soll. Der Datenbankadministrator kann zum Beispiel auf einem Testsystem herausfinden, wo sich die meisten Vorteile realisieren lassen.
Rainer Huttenloher

Tel: +49 8191 9649-0
Fax: +49 8191 70661
E-Mail: service @itp-verlag.de